Keys Assignments¶
Assignment 1: Internship Description¶
This summer I am working in Dr. Tyson L. Swetnam's Lab. He is a Research Assistant Professor of Geoinformatics with a joint appointment in the School of Natural Resources and the Environment. Dr. Swetnam is part of the CyVerse initiative: a National Science Foundation funded cyberinfrastructure that promotes open source data, science, and collaboration in the biosciences. Dr. Swetnam's research is focused on using cyberinfrastructure to support and encourage reproducible research, along with geospatial analysis. The Lab's current projects include Open Dendro, an initiative to restructure outdated dendrochronological software written in C, R, and Fortran into Python. Dr. Swetnam is involved in a plethora of other projects, but all of his projects show a commitment to open science through the use of open data and open software to promote reproducible research in information science. The primary project that I will be focused on this summer is the improvement of spatio-temporal asset catalog (STAC) catalogs for use in Google's Earth Engine. Each spatio-temporal asset is a file or dataset that contains information about the Earth captured at a specific time. By streamlining this process and working on making these datasets more accessible it ensures equal access and promotes open science.
Project Description¶
This summer I will be working on improving the STAC catalogs for the awesome-gee-community-datasets. This is a project spearheaded by Dr. Swetnam's former graduate student and colleague, Samapriya Roy. The project is focused on improving datasets for community use with Google's Earth Engine Catalog, a tool for mapping satellite and geospatial data across the Earth's surface to detect changes and trends. The awesome-gee-community-datasets are a set of community gathered and organized geospatial data that is preprocessed to allow for easy use with Google's Earth Engine. This summer I will work on improving the spatial-temporal asset (STAC) catalogs for these datasets to improve ease of use and access. A STAC catalog serves as a standardized way of storing and indexing geospatial data for easy discovery and use. This creates a common language and format that ensures previous code doesn't need to be rewritten, promoting open data, software, and science.
Assignment 2: Introduction to your Research¶
Purpose:¶
The purpose of my research is to standardize and process geospatial data for use with Google’s Earth Engine for planetary-scale geospatial analysis. This improvement and standardization of geospatial data will be conducted using spatio-temporal asset catalogs (STAC), which will help make these complex datasets easier to index and discover in order to perform analyses of Earth’s systems and conditions.
Previous Research:¶
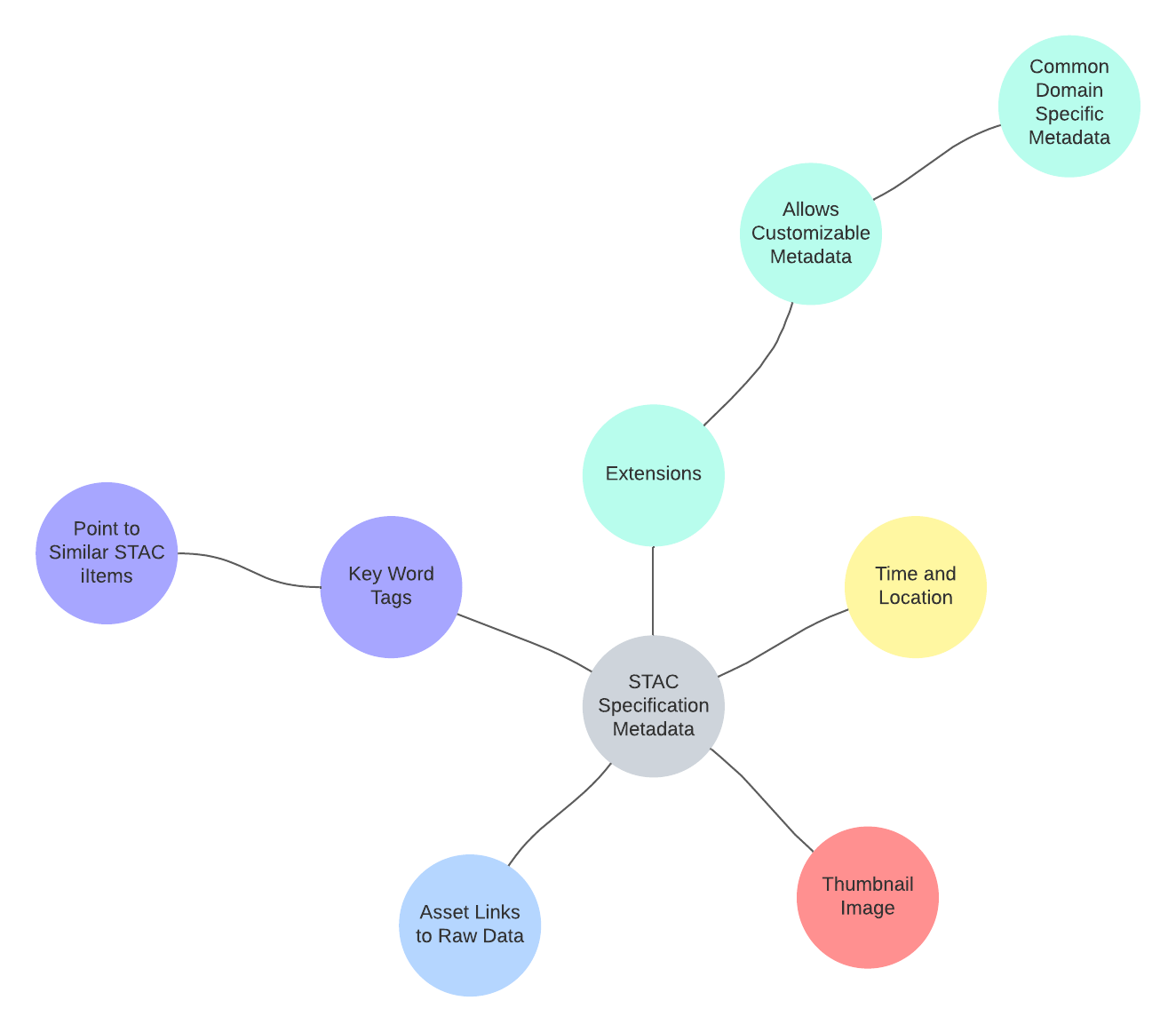
Oftentimes raw data is not ready for analysis, and it requires pre-processing. Additionally, this analysis often requires the installation and utilization of many different software packages. This is especially true for large datasets that are being used for planetary analysis on an Earth and solar system scale. However, the use of the spatio-temporal asset catalog (STAC) specification allows for the creation of metadata that allows datasets to be indexable and discoverable. A spatio-temporal asset is a type of Javascript object notation (JSON) file. This is a data interchange format that allows large raw datasets to be text based. The STAC specification designates the need for metadata on the time and location of the data, a thumbnail, links to the raw data, and key words that describe the relationship of the data, pointing to similar spatio-temporal assets. Following this specification furthers cloud based computing and means that these large geospatial datasets don’t need to be downloaded locally for planetary scale analysis. It is for these reasons that previous research has shown that the STAC specification is an important and highly useful method for designating metadata, especially for large planetary scale analysis (Fergason et al, 2018). Additionally, this STAC specification can be used for Google’s Earth Engine (GEE), established in 2010. GEE initially featured a data repository of global satellite data from the past 40 years; however, this has expanded to now include vector, climate, demographic, and elevation data that can be layered to perform complex global geospatial analyses. Users can also upload their own datasets and write scripts to analyze this data. The development of GEE as a free resource has helped to level the playing field and make large-scale geospatial analysis possible for a larger range of scientists, particularly those in developing countries (Kumar and Mutanga, 2018). However, a lot of this data that users are looking to use with GEE is not preproccessed, and STAC catalogs serve as a potential solution to this. My project will allow more equitable acces to a variety of geospatial data, promoting equality and open science. By improving the use of STAC catalogs it ensures that scientists have access to quality analysis tools like GEE and datasets that are easy to navigate.
Need For Study:¶
This study will further the use of STAC catalogs for geospatial data. Through this standardization, it will make Google’s Earth Engine more accessible to other researchers and data scientists. Pre-processing geospatial data and formatting it using STAC catalogs makes this data easier to index and search, allowing for its discovery. This concept of open data is crucial in regard to the open science movement. The production of open software and data allows key geospatial analysis tools to reach a larger number of researchers and scientists. With the threat of climate change and the necessity for immediate action, it is crucial to understand Earth’s systems and processes. Google’s Earth Engine allows for large-scale geospatial analysis that can help scientists visualize and understand concepts such as forest fire management and sea level change. The improvement of STAC catalogs for Google’s Earth Engine facilitates analysis and discovery that is crucial to understanding how to prevent climate change and preserve the natural environment.
Problem Statement:¶
Many current geospatial datasets are difficult to navigate, discover, and analyze. How can the organization of this data be improved to ensure ease of use, appropriate analysis, and equitable access?
References¶
Fergason, R. L., Hunter, M. A., Laura, J. R., Hare, T. M., & U.S. Geological Survey. (2021). Analysis Ready Data Available Through the SpatioTemporal Asset Catalog (STAC) Specification: Investigating the Application to Planetary Data. 5th Planetary Data and PSIDA 2021, 2549, 7023–7024. https://www.hou.usra.edu/meetings/planetdata2021/pdf/7023.pdf
Kumar, L., & Mutanga, O. (2018). Google Earth Engine Applications Since Inception: Usage, Trends, and Potential. Remote Sensing, 10(10), 1509. https://doi.org/10.3390/rs10101509
Assignment 3: Materials and Methods¶
To best standardize and organize geospatial data for use with Google’s Earth Engine I will use the Spatio-Temporal Asset Catalog (STAC) Specification. The STAC Specification is the leading standard for geospatial data because it allows for the creation of metadata (data that provides information on the datasets) that allows assets to be indexable and discoverable. By following this specification I will create metadata for the awesome-gee-community datasets to improve reproducibility and promote discovery.
Throughout this process I will use free software such as GitHub, VSCode, and Jupyter Notebooks to improve the metadata to align with the STAC Specification: - GitHub is a platform for software development that promotes collaboration and is committed to open science - VSCode is a code editor that provides syntax and debugging support - Jupyter Notebooks is a web-based computing platform that allows for the seamless integration of a code editor, terminal, and markdown files for documentation
This software will aid me in completing my project efficiently and effectively. Additionally, their free nature and public access aligns with my project’s mission of furthering open and equitable science.
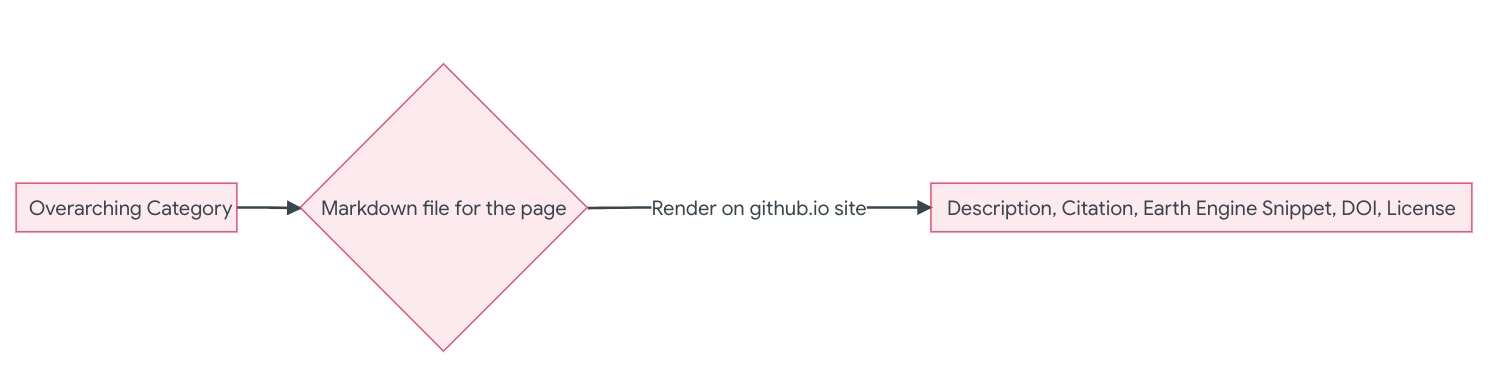
The initial organization of the awesome-gee-community datasets on GitHub is represented by this diagram:
Using the aforementioned software, I will use the coding languages of Python, Markdown, and Javascript to create and improve the awesome-gee-community datasets’ metadata to align with the STAC Specification, allowing its use with Google’s Earth Engine.
Assignment 4: Results¶
I’m still in the middle of conducting my research; therefore, I don’t have completed results yet. Additionally, my project is somewhat unconventional in nature, as I am processing and standardizing datasets. This means that I won’t have much numerical, collected data to graph or represent in charts. Instead, I plan to include information on which datasets I processed, and what the result of processing them was. I’m currently working with around 50 datasets; however, I’m not sure if I will work through all of these datasets during the internship and there is no logistical way to represent all of them on one poster. However, all of the datasets will be processed and standardized with the same template, producing a similar result but with different data. Therefore, my plan is to document the results of implementing this process for one example dataset, and then also include information on all of the other datasets that I processed. I haven’t begun this process yet because my PI is still working on finalizing the guidelines and template for the process; therefore, I’m not exactly sure what this will look like. I plan to represent my results mostly through visuals. I will include a screenshot of the final, processed spatio-temporal asset, along with a screenshot of this processed data visualized with Google Earth Engine that will look something like this:
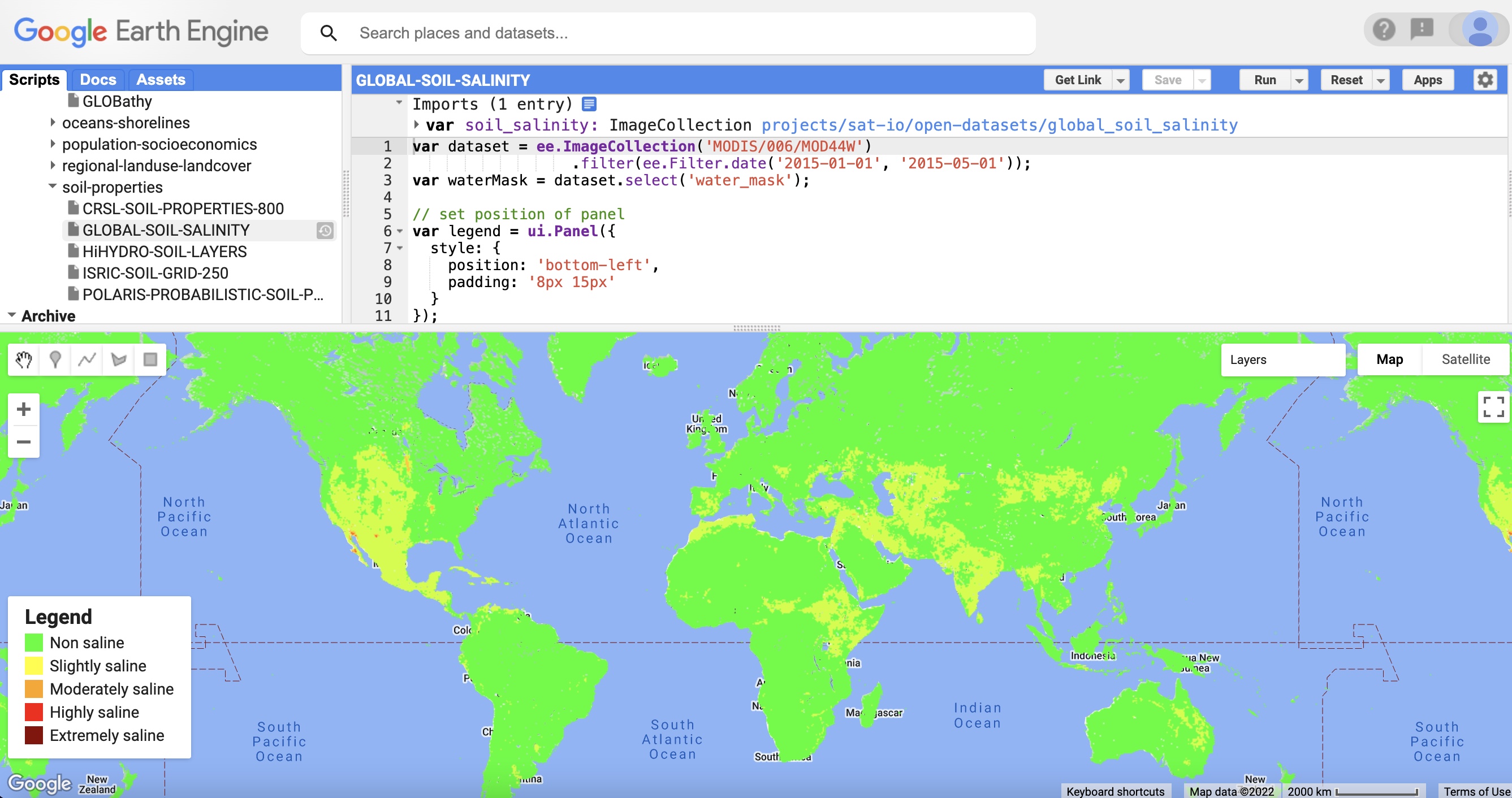
Ivushkin, Konstantin, Harm Bartholomeus, Arnold K. Bregt, Alim Pulatov, Bas Kempen, and Luis De Sousa. "Global mapping of soil salinity change." Remote sensing of environment 231 (2019): 111260.
I will then explain that all of the geospatial datasets were processed in this similar manner to achieve usable, standardized results. Additionally, I will include information on all of the geospatial data that I processed, along with what category it falls into, and its citation. I will represent this through a concept map/flowchart that will look something like this:
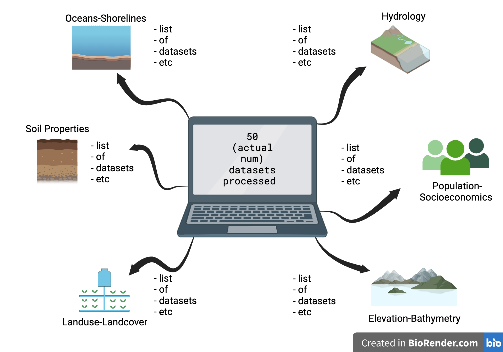 Fig 1. Visual representation for listing the names of the standardized data sets and their corresponding overall categories
Fig 1. Visual representation for listing the names of the standardized data sets and their corresponding overall categories
My project is all done through computing, and therefore there is a large volume of code that can’t be realistically all shown on my poster. However, throughout my internship I have been documenting my progress and results on a website I built. I need to further discuss this with my PI, but I also may include a QR code to my website under my results section for viewers who are interested in exploring my project more fully.

Website QR code for extra information on my project and process
Assignment 5 Long Abstract¶
Many geospatial datasets are difficult to access, require preprocessing, or the use of specialized software. This creates a problem for data scientists who are researching the Earth and performing planetary scale analyses: many of these datasets are hard to discover and navigate. In order to combat this issue, data standardization is necessary. The Spatio-Temporal Asset Catalog (STAC) specification provides a solution to this by designating the creation of metadata for each set of geospatial data, improving indexability and discovery. This data can be visualized and analyzed through Google’s Earth Engine (GEE), a cloud based computing platform that allows for powerful, planetary scale geospatial analysis. We employed this standardization technique for Dr. Samapriya Roy’s Awesome-Gee-Community-Datasets, a GitHub repository of over 850 geospatial datasets that can be analyzed and understood through GEE. By narrowing in on a subset of 49 of these datasets, Dr. Roy created a template that designated the creation and standardization of metadata for each of these datasets. This designated the need for information including a description, source data structure, GEE code snippet, license, and citation. This final, standardized metadata was displayed on the community datasets GitHub website, providing data scientists further knowledge on how to use, cite, and discover this data for analysis with GEE. Standardizing this data promotes discovery and the principles of open science, ensuring equity within computing through open data and open code. This is crucial as scientists work collaboratively to understand the planet’s systems and processes to better combat climate change.
Assignment 6 Conclusion and Discussion¶
Due to the complex nature of large geospatial datasets, they can be difficult to analyze, requiring large amounts of preprocessing or software, stunting collaboration and scientific progress. This process for the standardization of the Community Datasets’ metadata was successful in creating a more uniform format. By editing the MarkDown files to ensure the documentation was uniform throughout, it improved the user interface for the Community Datasets repository. We were not able to work through all of the forty-nine dataset subset, which was largely due to the long period of background research. In order to understand the current organizational status of the repository, and thus assess how to best standardize it, a significant period of time was spent taking notes and data on the initial state of the repository. While time consuming, this was a crucial step to ensure a replicable and effective technique for standardization, even if it meant sacrificing the quantity of standardized datasets. Additionally, some template elements, particularly the source data structure, were difficult, or not possible at this time, to ascertain. This meant that some of the standardized datasets did not perfectly match the initial template. Although some of the datasets did not align perfectly, the integrity of the project was still preserved, as usability and organization was still improved. This project will be continued to extend to the other datasets in the repository, hopefully eventually working through all remaining datasets, and ensuring that new datasets meet the specification when added to the repository. By improving the access and structure of these datasets, their discoverability is also improved. This upholds the tenets of open science through the principles of open data and open code. This plays an important role in improving equity and collaboration in computing. By providing data scientists increased and improved tools for analysis and discovery, it helps further understanding of Earth’s systems and processes, helping us build a more unbiased, conscientious, and aware society.
Assignment 7 Title and Short Abstract¶
Title¶
Data Standardization: Improving Usability of Geospatial Data for Google Earth Engine
Short Abstract¶
Many geospatial datasets are difficult to access, navigate, and require preprocessing, creating a problem for data scientists performing planetary scale analyses. Data standardization creates a uniform structure, improving usability. The Spatio-Temporal Asset Catalog (STAC) specification designates the metadata for geospatial datasets. Using the principles of the STAC specification, we began standardizing Dr. Samapriya Roy’s Awesome-Gee-Community-Datasets, a GitHub repository of 850+ Google Earth Engine (GEE), a platform for planetary geospatial analysis, datasets. The standardized metadata provides data scientists knowledge on how to use and understand the Awesome-Gee-Community-Datasets for GEE analysis. Standardization promotes discovery and open science, ensuring equity within computing and helping scientists work to understand Earth’s processes, building a more aware and conscientious society.